詳細な良い記事-12306.cnからの大規模なWebサイトのアーキテクチャとパフォーマンスの最適化について話します
12306.cnウェブサイトがダウンしています,全国の人に叱られる。私はこの2日間これについて考えていました,私はあなたとウェブサイトのパフォーマンスの問題を大まかに議論するためにこの問題を使用したいと思います。急いで,そして、私の限られた経験と理解に完全に基づいています,など,ご不明な点がございましたら、一緒に話し合い、修正してください。(これは別の長い記事です,パフォーマンスの問題についてのみ話し合う,それらのUIについて話し合わないでください,ユーザー体験,それとも、支払いとチケットの注文を分離する機能的なものですか?)
仕事
ビジネスニーズなしではテクノロジーは成り立ちません,など,パフォーマンスの問題を説明するため,まずはビジネスの問題についてお話したいと思います。
- 1,誰かがこれをQQやオンラインゲームと比較するかもしれません。しかし、私は2つが異なると思います,オンラインゲームとQQオンライン、またはログイン時に、ユーザー自身のデータにアクセスします,チケット予約システムは、センターのチケットボリュームデータにアクセスします,それは同じではありません。オンラインゲームやQQが機能するとは思わないでください。同じだと思います。。eコマースシステムと比較して、オンラインゲームとQQのバックエンドロードは依然として単純です。
- 2番目,春節の間に電車を予約するのは、ウェブサイトでの急上昇のようなものだと言う人もいます。。確かに非常に似ています,しかし、あなたの考えが表面にない場合,これも少し違うことがわかります。列車のチケット,一方では、多数のクエリ操作が伴います,さらにBTは、注文時にデータベースに対して一貫した操作が多数行われることです。,一方では、開始点から終了点までの各セグメントチケットの一貫性,一方,バイヤールート、列車番号、多くの時間オプションがあります,注文の仕方を常に変えていきます。そしてスパイク,直接殺すだけ,クエリや一貫性の問題はそれほど多くありません。加えて,スパイクについて,最初のN人のユーザーの要求のみを受け入れるようにすることができます(バックエンドでデータをまったく操作しないでください), ユーザーの注文操作をログに記録するだけです),この種のビジネス,スパイクの数をメモリキャッシュに入れるだけで済みます,データを配布することもできます,100商品,10各サーバーは10を置きます,一度にデータベースを操作する必要はありません。あなたは十分に注文することができます,スパイクを停止します,次に、データベースへのバッチ書き込み。そして、スパイクには多くの製品がありません。列車の切符はスパイクほど単純ではありません,春節の時間,ほとんどすべてのチケットはホットチケットです,そして、全国のほぼすべての人々がここにいます,そして、転送ビジネスもあります,複数行の在庫はトランザクション操作である必要があります,考えてみてください,これはどれくらい難しいですか。(淘宝網のダブルイレブンには300万人のユーザーがいます,そして、列車の切符は即座に数千万、さらには数億になります)(更新する:20141月11日:淘宝網に来てから,淘宝網のシステムを理解している,淘宝網のスパイク活動,基本的に、検証コードを使用して、CDNで直接ユーザーを除外します,といった:1数千万人のユーザーがフィルタリングされ、20,000人のユーザーだけが残ります,このようにして、データベースは耐えることができます)
- 三番目,誰かがこのシステムをオリンピックのチケットシステムと比較します。まだ違うと思います。オリンピックのチケットシステムは発売と同時に廃止されましたが。しかし、オリンピックは宝くじ抽選を使用します,言い換えれば、先着順の方法はありません,そして,後付けです,事前に情報を受け取るだけです,事前にデータの一貫性を確保する必要はありません,ロックなし,水平方向のスケーリングが簡単。
- 第4,予約システムは、eコマース注文システムと非常によく似ている必要があります,すべてがインベントリを実行する必要があります:1)在庫を占有する,2)支払い(オプション),3)在庫を差し引く操作。これは一貫性をチェックする必要があります,つまり、同時実行中にデータをロックする必要があります。B2Ceコマースは基本的にこれを非同期で行います,言い換えると,ご注文はすぐには処理されません,しかし、処理が遅れる,正常に処理されただけ,注文が成功したことを知らせる確認メールが送信されます。多くの友人が失敗した電子メールを受け取ったと思います。この意味は,データの一貫性は同時実行性のボトルネックです。
- 5番,鉄道切符事業が異常,突然のチケットリリースを使用しています,そして、いくつかの投票は誰にとっても十分ではありません,など,誰もが中国の特徴を持つビジネスのチケットを手に入れる練習をします。だからチケットがリリースされたとき,数百万または数千万人が殺されます,お問い合わせ,注文する。数十分以内,ウェブサイトは数千万の訪問を受けることができます,これはひどいことです。12306のピーク訪問は10億PVと言われています,午前8時から午前10時に焦点を当てる,ピーク時に毎秒数千万のPV。
もう少し言葉を言ってください:
- 在庫はB2Cの悪夢です,在庫管理は非常に複雑です。不信,あなたはすべての伝統的な電気小売会社に尋ねることができます,彼らが在庫を管理するのがどれほど難しいかを見てください。さもないと,Vanclの在庫について質問する人はそれほど多くありません。(「ジョブズバイオグラフィー」もご覧いただけます,ティムがアップルのCEOに就任した理由をご存知でしょう,主な理由は、彼がAppleの在庫サイクルの問題を修正したことです)
- ウェブサイトの場合,Webを閲覧する負荷が高いため、処理が簡単です。,クエリの負荷には、対処するのにある程度の難易度があります,ただし、クエリ結果をキャッシュすることで実行できます。,最も難しい部分は注文の負荷です。在庫にアクセスする必要があるため,ご注文の際,基本的には非同期で行われます。昨年はダブル11,淘宝網の1時間あたりの注文数は約60万件です,Jingdongは1日で400,000しかサポートできません(12306より悪いです),Amazonは5年前に1時間で700,000件の注文をサポートできました。見える,発注操作は私たちほど高くはありません。
- 淘宝網はB2Cウェブサイトよりもはるかにシンプルです,倉庫がないので,など,同じ製品在庫を更新および照会するためのN個の倉庫を持つB2Cのような操作はありません。。ご注文時,B2Cのウェブサイトは倉庫を見つけようとしています,再びユーザーに近づく,再度インベントリ,これには多くの計算が必要です。ただ想像します,あなたは北京で本を買いました,北京の倉庫は在庫切れです,周辺の倉庫から移動する必要があります,次に、瀋陽または西安の倉庫に在庫があるかどうかを確認します,ない場合,私は江蘇省の倉庫を見なければなりません,などなど。淘宝網にはそれほど多くのものはありません,各マーチャントには独自の在庫があります,在庫は数です,そして、在庫は商人に割り当てられます,パフォーマンスの向上につながります。
- データの一貫性が実際のパフォーマンスのボトルネックです。nginxは1秒あたり100,000の静的リクエストを処理できると言う人もいます,間違いない。しかし、これは単なる静的な要求です,理論値,帯域幅がある限り、I / Oは十分に強力です,サーバーの計算能力は十分です,また、サポートされる同時接続の数は、100,000のTCPリンクの確立に耐えることができます,それは問題ありません。しかし、データの一貫性に直面して,この100,000は完全に達成不可能な理論値になっています。
たくさん言った,私はただビジネスからみんなに伝えたいです,春節鉄道の切符予約事業の異常を事業から真に理解する必要があります。。
フロントエンドのパフォーマンス最適化テクノロジー
パフォーマンスの問題を解決するには,一般的に使用される方法はたくさんあります,以下にリストします,以下の技術を使用した12306のウェブサイトは、そのパフォーマンスを質的に飛躍させると信じています。。
1、フロントエンドの負荷分散
DNSロードバランサー(通常はルートの負荷リダイレクトに応じてルーター上)を介して、ユーザーのアクセスを複数のWebサーバーに均等に分散できます。。これにより、Webサーバーのリクエスト負荷を減らすことができます。httpリクエストは短い仕事なので,など,この機能は、非常にシンプルなロードバランサーを介して実行できます。ユーザーが最寄りのサーバーに接続できるように、CDNネットワークを用意することをお勧めします(CDNには通常分散ストレージが付属しています)。(負荷分散の詳細については、「バックエンド負荷分散」を参照してください)
二、フロントエンドリンクの数を減らす
12306.cnを見てみました,ホームページを開くには、60を超えるHTTP接続が必要です,チケット予約ページには70を超えるHTTPリクエストがあります,現在のブラウザはすべて同時リクエストです(もちろん,ブラウザの同時ページ数は制限されています,ただし、ユーザーが複数のページを開くのを止めることはできません,そして,バックエンドサーバーのTCP接続はフロントエンドから始まります,すぐにリリースされたり、重要になったりすることはありません)。など,100万人のユーザーがいる限り,6000万のリンクがあるかもしれません(最初の訪問の後、ブラウザ側のキャッシュがあります,この数は減ります,20%だけが数百万のリンクであっても),過度に。ただのログインクエリページ。ファイルにjsと入力します,ファイルにcssと入力します,アイコンをファイルに入力します,cssブロックで表示。リンクの数を最小限に抑える。
三、Webページのサイズを縮小し、帯域幅を拡大します
この世界のすべての企業が画像サービスを敢えて行うわけではありません,画像が帯域幅を消費しすぎるため。昨今のブロードバンド時代では、ダイヤルアップ時代の写真ページを作るときに、あえて写真を使わない状況を誰もが理解することは困難です(これは今の携帯電話での閲覧にも当てはまります)。。ダウンロードが必要な12306ホームページの合計ファイルサイズが約900KBであることを確認しました,あなたが訪問した場合,ブラウザはあなたのためにたくさんキャッシュします,約10Kのファイルをダウンロードするだけです。しかし、私たちは極端なケースを想像することができます,1何百万人ものユーザーが同時に訪問します,そして、それは訪問するのは初めてです,1人あたり100万ダウンロード,120秒以内に戻る必要がある場合,次に、あなたが必要です,1M * 1M /120 * 8 = 66Gbps帯域幅。素晴らしいです。など,その日だと思います,12306輻輳は基本的にネットワーク帯域幅である必要があります,など,あなたが見るかもしれないものは無応答です。後で、ブラウザのキャッシュは12306が多くの帯域幅使用量を削減するのに役立ちます,したがって、負荷はバックエンドに到着します,バックエンドのデータ処理のボトルネックがすぐに発生します。したがって、http500のような多くのエラーが表示されます。これは、バックエンドサーバーがダウンしていることを示しています。
四、静的フロントエンドページ
頻繁に変更されない一部のページとデータを静的化する,そしてそれをgzipで圧縮します。別の倒錯した方法は、これらの静的ページを/ dev / shmの下に置くことです。,このディレクトリはメモリです,メモリから直接ファイルを読み取り、,これにより、高価なディスクI / Oを削減できます。nginxのsendfile関数を使用して、これらの静的ファイルを内部コア状態で直接交換できるようにします,パフォーマンスを大幅に向上させることができます。
五、クエリを最適化する
多くの人の質問が同じものを探しています,リバースプロキシを使用して、これらの同時同一クエリをマージすることは完全に可能です。。このようなテクノロジーは、主にクエリ結果のキャッシュによって実装されます,初めてデータベースにクエリを実行してデータを取得する,そして、データをキャッシュに入れます,以降のすべてのクエリは、キャッシュに直接アクセスします。クエリごとにハッシュ,NoSQLテクノロジーを使用してこの最適化を完了します。(この手法は静的ページにも使用できます)
列車の切符の数量のクエリ用,数字を表示したくない,「はい」または「なし」を表示するだけです,これにより、システムの複雑さが大幅に簡素化されます,そしてパフォーマンスを向上させる。データベース上のクエリの負荷を分離します,データベースが注文した人により良いサービスを提供できるように。
六、キャッシュの問題
キャッシュを使用して動的ページをキャッシュできます,クエリデータのキャッシュにも使用できます。通常、キャッシングにはいくつかの問題があります:
1)キャッシュされた更新。キャッシュとデータベースの同期とも呼ばれます。いくつかの方法があります,1つはタイムアウトをキャッシュすることです,キャッシュを無効にする,再確認,2つは,バックエンド通知による更新,バックエンドの変更,フロントエンドの更新を通知する。前者は実装が比較的簡単です,しかし、リアルタイムのパフォーマンスは高くありません,後者は実装がより複雑です ,しかし、高いリアルタイム。
2)キャッシュされたページフィード。メモリが不足している可能性があります,など,一部の非アクティブなデータをメモリからスワップアウトする必要があります,これは、オペレーティングシステムのメモリページングおよびスワッピングメモリと非常によく似ています。。FIFO、LRU、LFUは比較的古典的なページ変更アルゴリズムです。関連コンテンツを参照してくださいWikipeidaのキャッシュアルゴリズム。
3)キャッシュの再構築と永続性。メモリにキャッシュ,システムは常に維持する必要があります,など,キャッシュは失われます,キャッシュがなくなった場合,再構築する必要があります,データ量が多い場合,キャッシュの再構築プロセスは遅くなります,これは本番環境に影響します,など,キャッシュの永続性も考慮する必要があります。
多くの強力なNoSQLは、上記の3つの主要なキャッシュの問題を非常によくサポートしています。。
バックエンドのパフォーマンス最適化テクノロジー
フロントエンドパフォーマンスの最適化テクノロジーについては前に説明しました,したがって、フロントエンドはボトルネックの問題ではない可能性があります。次に、パフォーマンスの問題がバックエンドデータに発生します。バックエンドでの一般的なパフォーマンス最適化手法をいくつか示します。。
1、データの冗長性
データの冗長性について,言い換えると,データベース内のデータの冗長処理,これは、テーブル結合などのコストのかかる操作を削減するためです。,しかし、これはデータの一貫性を犠牲にします。比較的高いリスク。多くの人がデータにNoSQLを使用しています,すぐに,データが冗長であるため,しかし、これはデータの一貫性に対する大きなリスクです。これは、さまざまなビジネスに従って分析および処理する必要があります。(知らせ:リレーショナルデータベースを使用してNoSQLに簡単に移植できます,ただし、NoSQLからリレーショナルへの逆は困難です)
二、データミラーリング
ほとんどすべての主流データベースはミラーリングをサポートしています,これはレプリケーションです。データベースミラーリングの利点は、負荷分散を実行できることです。。1つのデータベースの負荷を複数のデータベースに均等に分割します,同時に、データの一貫性が保証されます(OracleのSCN)。最も重要なのは,これも高可用性を実現できます,1つは役に立たない,稼働中の別のものがあります。
データミラーリングのデータの一貫性は複雑な問題になる可能性があります,したがって、データを1つのデータに分割する必要があります,言い換えると,ベストセラー製品の在庫を異なるサーバーに均等に分割します,といった,ベストセラー商品の在庫は10,000,10台のサーバーを設置できます,各サーバーに1000のインベントリ,それはB2C倉庫のようなものです。
三、データパーティション
データミラーリングで解決できない問題の1つは、データテーブルにレコードが多すぎることです。,データベース操作が遅すぎる原因。など,パーティションデータ。データを分割する方法はたくさんあります,一般的に、次のようなものがあります:
1)データを特定のロジックに分類します。たとえば、列車のチケット予約システムは、鉄道局によって分割することができます,さまざまなモデルに分けることができます,発信局で分割可能,目的地ごとに分けることができます...,とにかく、それはテーブルを同じフィールドで異なるタイプの複数のテーブルに分割することです,そのような,これらのテーブルは、負荷分散の目的を達成するために異なるマシンに保存できます。
2)データをフィールドに分割します,つまり、垂直サブテーブル。たとえば、頻繁に変更されないデータをテーブルに配置します,頻繁に変更されるデータは他のテーブルに配置されます。テーブルを1対1の関係に変える,そのような,テーブルのフィールド数を減らすことができます,また、特定のパフォーマンスを向上させることができます。加えて,フィールドが増えると、レコードのストレージが別のページテーブルに配置されます,これには、読み取りと書き込みのパフォーマンスに問題があります。しかし、このように多くの複雑なコントロールがあります。
3)平均スコア表。最初の方法は必ずしも均等に分割されていないため,たぶん、ある種のデータはまだたくさんあります。など,均等配分方法もあります,主キーIDの範囲でテーブルを配布します。
4)同じデータパーティション。これは上記のデータミラーに記載されています。つまり、同じ製品の在庫値が異なるサーバーに割り当てられます,たとえば、10,000の在庫があります,10台のサーバーに分割できます,1台のマシンに1000株。次に負荷分散。
3つのパーティションはすべて良い点と悪い点です。最も一般的に使用されるのは最初のものです。データが分割されたら,フロントエンドプログラムにデータの場所を知らせるには、1つ以上のスケジュールが必要です。。列車の切符のデータを分割する,そしてそれをさまざまな州や都市に置きます,これにより、12306システムの質的なパフォーマンスが大幅に向上します。。
四、バックエンドシステムの負荷分散
データパーティションについては前述しました,データ分割により、負荷をある程度軽減できます,しかし、売れ筋商品の負荷を減らすことはできません,列車の切符の場合,大都市のいくつかの幹線のチケットと見なすことができます。これには、負荷を軽減するためにデータミラーリングを使用する必要があります。データミラーリングを使用する,負荷分散を使用する必要があります,バックエンド,ルーターのようなロードバランサーを使用するのは難しいかもしれません,トラフィックのバランスを取るため,トラフィックはサーバーのビジー状態を示していないため。したがって、,タスク分散システムが必要です,また、各サーバーの負荷を監視することもできます。
タスク分散サーバーにはいくつかの問題があります:
- 負荷状況はより複雑です。何が忙しいですか? CPUは高いですか?または、ディスクI / Oは高いですか?またはメモリ使用量が多いですか?それとも並行性は高いですか?または、メモリページレートが高いですか?あなたはすべてを考慮する必要があるかもしれません。この情報は、そのタスクディストリビューターに送信する必要があります,タスクディストリビューターは、処理する負荷が最も軽いサーバーを選択します。
- タスクキュー,タスクを失うことはできません,だからそれは持続する必要があります。また、タスクをコンピューティングサーバーにバッチで割り当てることができます。
- タスク分散サーバーが停止している場合はどうすればよいですか?ここでは、Live-Standbyやフェイルオーバーなどの高可用性テクノロジーが必要です。。また、永続タスクのキューが他のサーバーに転送される方法にも注意を払う必要があります。。
多くのシステムが静的割り当てを使用していることがわかります,ハッシュを使用するものもあります,分析するために交代で行う人もいます。これらは十分ではありません,1つは、負荷のバランスを完全にとることができないことです。,静的メソッドのもう1つの致命的な欠陥は,コンピューティングサーバーがクラッシュした場合,または、新しいサーバーを追加する必要があります,私たちのディストリビューターのために,すべてが知る必要があります。加えて,また、ハッシュを再計算します(コンシステントハッシュはこの問題を部分的に解決できます)。
別の方法は、負荷分散にプリエンプティブな方法を使用することです,ダウンストリームコンピューティングサーバーからタスクサーバーへタスクを取得する。これらのコンピューティングサーバーに、タスクが必要かどうかを判断させます。これには、システムの複雑さを単純化するという利点があります,また、コンピューティングサーバーをリアルタイムで任意に増減することもできます。しかし、唯一の悪いことは,特定のサーバーでのみ処理できるタスクがある場合,これにより、複雑さが生じる可能性があります。しかし全体的に,この方法は、より優れた負荷分散になる可能性があります。
五、非同期、 スロットルとバッチ処理
非同期、スロットル(スロットルバルブ)とバッチ処理の両方で、同時リクエストの数をキューに入れる必要があります。
- 非同期は通常、ビジネスでリクエストを収集することです,その後、処理を遅らせます。技術的には、各処理プログラムを並列化できます,水平方向に拡張できます。しかし、非同期の技術的な問題にはおそらくこれらがあります,a)呼び出し先の結果が返されます,プロセススレッド間の通信の問題が発生します。b)プログラムをロールバックする必要がある場合,ロールバックは少し複雑になります。c)非同期には通常、複数のスレッドと複数のプロセスが伴います,同時実行制御も比較的面倒です。d)多くの非同期システムはメッセージメカニズムを使用します,メッセージの喪失と混乱もより複雑な問題になります。
- スロットルテクノロジーは実際にはパフォーマンスを向上させません,このテクノロジーは、主に、システムが処理できないトラフィックに圧倒されるのを防ぐためのものです。,これは実際には保護メカニズムです。スロットルテクノロジーの使用は、通常、制御できない一部のシステムに使用されます。,といった,あなたのウェブサイトに接続された銀行システム。
- バッチ処理技術,基本的に同じリクエストの束をバッチで処理することです。といった,誰もが同時に同じ製品を購入します,購入する必要はありません。データベースを一度作成します。,一定数のリクエストを収集できます,1回の操作。この手法はさまざまな方法で使用できます。ネットワーク帯域幅の節約など,私たちは皆、ネットワーク上のMTU(Maximum Transmission Unit)を知っています,状態ネットワークは1500バイトです,光ファイバは4000バイト以上に達する可能性があります,ネットワークパケットの1つがこのMTUを満たさない場合,それはネットワーク帯域幅を浪費しています,ネットワークカードのドライバは1枚ずつしか読み取れないため、効率が高くなります。。したがって、,ネットワークが送信されるとき,ネットワークI / Oを実行する前に、十分な情報を収集する必要があります,これはバッチ処理の方法でもあります。バッチ処理の敵はトラフィックが少ないことです,など,バッチ処理システムは通常、2つのしきい値を設定します,1つは仕事量です,もう1つはタイムアウトです,1つの条件が満たされている限り,提出プロセスを開始します。
など,非同期である限り,一般的にスロットル機構があります,通常、キューに入れるキューがあります,キューがあります,永続性があります,システムは通常、バッチ処理を使用します。
Yunfengによって設計された「キューイングシステム」 このテクノロジーは。これはeコマース注文システムと非常によく似ています,あれは,私のシステムはあなたのチケット購入リクエストを受け取りました,しかし、私はまだそれを実際に扱っていません,私のシステムは、私自身の処理能力に従って、これらの大量のリクエストを抑制します,そして少しずつそれに対処します。処理が完了したら,メールやテキストメッセージを送信して、実際にチケットを購入できることをユーザーに伝えることができます。
ここにあります,Yunfengのキューイングシステムについて、ビジネスとユーザーのニーズを通じて説明したいと思います。,この問題を技術的に解決しているように見えるからです,しかし、ビジネスとユーザーのニーズに関しては、深く考える価値のあるポイントがまだいくつかあるかもしれません。:
1)。キューに対するDoS攻撃。まず第一に,考えてみよう,このチームは単に列に並んでいますか?それは十分ではありません,このため、スカルパーを止めることはできません,また、単純なticket_idはDoS攻撃を受けやすい,といった,Nticket_idを開始しました,チケット購入プロセスに入った後,買わない,私はあなたに30分を消費します,チケットを購入したい人が数日間チケットを購入できないようにするのは簡単です。誰かが言った,ユーザーはIDカードを使用してキューに入れる必要があります, このように、あなたは購入するためにこのIDカードを使用する必要があります,しかし、これでもイエローステーキチームや入稿担当者を止めることはできません。N個のアカウントを登録してキューに入れることができるからです,しかし、ただ買わないでください。スカルパーのような人は、現時点で1つのことをするだけで済みます,人々がそれにアクセスできないようにウェブサイトを非常に普通にする,ユーザーが自分だけで購入できるようにする。
2)。コンコーダンス?このキューでの操作にはロックが必要ですか?ロックがある限り,パフォーマンスが上がってはいけません。ただ想像します,1001万人が同時にロケーション番号を割り当てるように求めます,このキューはパフォーマンスのボトルネックになります。良好なパフォーマンスを実現するには、データベースがない必要があります,など,今より悪いかもしれません。データベースの取得とキューの取得は基本的に同じです。
3)。キューの待機時間。チケットを買うのに30分で十分ですか?過度に?その時点でユーザーがたまたまインターネットにアクセスできなかった場合はどうなりますか?時間が短い場合,操作するのに十分な時間がない場合、ユーザーは不平を言うでしょう,時間がかかる場合,後ろに並んでいる人も文句を言うでしょう。この方法は、実際の操作で多くの問題が発生する可能性があります。加えて,30分は長すぎます,これは完全に非現実的です,例として15分を使用しましょう:1000万人のユーザー,一瞬一瞬に入れられるのは10,000個だけ,これらの10,000人のユーザーは、すべての操作を完了するのに15分かかります,その後、,これらの1,000万人のユーザーすべてが処理されました,1000 * 15m = 250時間が必要,10半日,電車は早く出発した。(私はそれについて話していません,鉄道省の専門家によると:最近,1日あたり平均100万件の注文,など,1000万人のユーザーを処理するのに10日かかります。この計算は少し簡単かもしれません,言いたいだけ,このような低負荷システムでは、キューイングによってビジネス上の問題が解決されない場合があります。)。
4)。分散キュー。このキューイングシステムにはキューが1つしかありませんか?十分じゃない。なぜなら,切符を買える人を入れる場合、同じ電車で同じ種類の切符を買う場合(EMUの寝台など),それはまだチケットをつかんでいます,つまり、システムの負荷がサーバーの1つに集中している可能性があります。。したがって、,最善の方法は、ユーザーのニーズに応じて出発地と目的地を提供することです,ユーザーをキューに入れるには。そしてこのように,複数のキューが存在する可能性があります,複数のキューである限り,水平方向に拡大縮小できます。これにより、パフォーマンスの問題を解決できます,しかし、それはユーザーの長いキューの問題を解決しませんでした。
オンラインショッピングから学べると思います。キューイング時(注文時),ユーザーの情報と購入したいチケットを収集します,また、ユーザーがチケット購入の優先順位を設定できるようにします,といった,電車Aの寝台車を購入できない場合は、電車Bの寝台車を購入してください,それでもハードシートなどが買えない場合など,次に、ユーザーは最初に必要なお金を再充電します,次のステップは、システムが完全に自動的に非同期で注文を処理することです。SMSまたは電子メールを送信して、ユーザーが成功または失敗した場合にユーザーに通知します。そのような,システムは、ユーザー操作時間を30分節約できるだけではありません。,自動化して処理を高速化,同じチケット購入リクエストを持つ人々をマージすることもできます,バッチ処理を実行します(データベース操作の数を減らします)。この方法の最も良い点は、これらのキューに入れられたユーザーのニーズを知ることができることです。,ユーザーのキューを最適化できるだけでなく,ユーザーを異なるキューに分散する,アマゾンのウィッシュリストのようにすることもできます,いくつかの計算を通じて、鉄道省は列車の時間の全体的な調整と調整を行うことができます。(ついに,キューイングシステム(注文システム)は、データベースに保存するか、永続化する必要があります,ただメモリに入れることはできません,そうしないと、マシンがダウンします,叱られるのを待つだけ)。
まとめ
たくさん書いた,要約させてください:
0)。どのようにデザインしても,システムは簡単に拡張できる必要があります。言い換えると,データストリーム全体で,すべてのリンクは水平方向に拡張できる必要があります。そのような,システムにパフォーマンスの問題がある場合,「サーバーの30倍」は嘲笑されません。
1)。上記の技術は一夜にして行うことはできません,長期的な蓄積はありません,基本的に絶望的。私たちはそれを見ることができます,どちらを使用しても、多少の複雑さが発生します,デザインは常にトレードオフを行っています。
2)チケットの販売を一元化するのは難しい,上記の技術を使用すると、チケット予約システムのパフォーマンスを何百回も向上させることができます。にいる間さまざまな州や都市での変電所の建設,チケットを個別に販売する,既存のシステムのパフォーマンスを定性的に改善するための最良の方法です。
3)。春運の旅行シーズンの前夜にチケットを手に入れ、チケットの供給が需要よりはるかに少ないというビジネスモデルは非常に異常です。,何千万人、あるいは何億人もの人々が朝の8時に同時にログインし、同時にチケットを手に入れることを可能にするビジネスモデルは、倒錯の倒錯です。。経営状況の異常は、彼らが何をしても叱られることを決定します。
4)。こんなに大きなシステムを1、2週間構築する,そして残りの時間はアイドルです,同情,これが鉄道でできることです。。
2012年9月27日更新
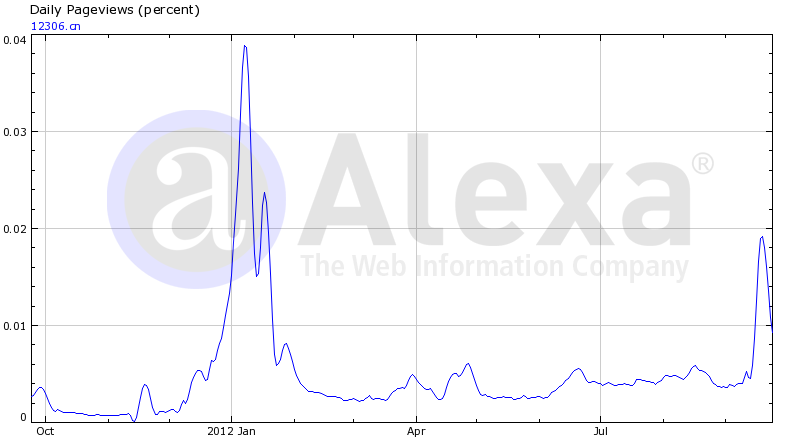
Alexaによってカウントされた12306のPV (ノート:AlexaPVの定義は次のとおりです。:ユーザーが1日にページを複数回クリックした場合、1回としてカウントされます)
((この記事を転載する際は、著者と出典を明記してください,商業目的を覚えていない)。
からの転送:http://coolshell.cn/articles/6470.html